Smacc: a Compiler-Compiler
A First SmaCC Tutorial
This tutorial demonstrates the basic features of SmaCC, the Smalltalk Compiler Compiler. We will use SmaCC to create a simple calculator. This tutorial was originally developed by Don Roberts and John Brant, and later modified by T. Goubier, S. Ducasse, J. Lecerf and Andrew Black.
Opening the Tools
Once you have loaded the code of SmaCC, you should open the SmaCC Parser Generator tool (Figure ). In Pharo, you can do this using the Tools submenu of the World menu.
Our first calculator is going to be relatively simple. It is going to take two numbers and add them together. To use the SmaCC tool:
- Edit the definition in the pane below the buttons.
- Once you are done:
- Accept (with the context menu) or Save (the button)
- Name your parser (and scanner) by typing a name (for example, CalculatorParser) in the text field at the left of the Parser label, followed by return.
- press either Compiler LR(1) or Compiled LALR(1) buttons to compile the parser.
You are now ready to edit your first scanner and parser. Note that you edit everything in one file (using the SmaCC tool). Once compiled, the tools will generate two classes and fill them with sufficient information to create the scanner and parser, as shown as Figure .
First, the Scanner
To start things off, we have to tell the scanner how to recognize a number. A number starts with one or more digits, possibly followed by a decimal point with zero or more digits after it. The scanner definition for this token (called a token specification) is:
<number> : [0-9]+ (\. [0-9]*) ? ;Let's go over each part:
<number>- Names the token identified by the token specification. The name inside the <> must be a legal Pharo variable name.
:- Separates the name of the token from the token's definition.
[0-9]- Matches any single character in the range
'0'to'9'(a digit). We could also use\dor<isDigit>as these also match digits. +- Matches the previous expression one or more times. In this case, we are matching one or more digits.
( ... )- Groups subexpressions. In this case we are grouping the decimal point and the numbers following the decimal point.
\.- Matches the '.' character (
.has a special meaning in regular expressions;\quotes it). *- Matches the previous expression zero or more times.
?- Matches the previous expression zero or one time (i.e., it is optional).
;- Terminates a token specification.
Ignoring Whitespace
We don't want to have to worry about whitespace in our language, so we need to define what whitespace is, and tell SmaCC to ignore it. To do this, enter the following token specification on the next line:
<whitespace> : \s+;
\s matches any whitespace character (space, tab, linefeed, etc.). So how do we tell the scanner to ignore it? If you look in the SmaCCScanner class (the superclass of all the scanners created by SmaCC), you will find a method named whitespace. If a scanner understands a method that has the same name as a token name, that method will be executed whenever the scanner matches that kind of token. As you can see, the SmaCCScanner>>whitespace method eats whitespace.
SmaCCScanner >> whitespace
"By default, eat the whitespace"
self resetScanner.
^ self scanForToken
SmaCCScanner also defines a comment method. That method both ignores the comment token (does not create a token for the parser) and stores the interval in the source where the comment occurred in the comments instance variable.
SmaCCScanner >> comment
comments add: (Array with: start + 1 with: matchEnd).
^ self whitespace
The only other token that will appear in our system is the + token for addition. However, since this token is a constant, there is no need to define it as a token in the scanner. Instead, we will enter it directly (as a quoted string) in the grammar rules
that define the parser.
Second, the Calculator Grammar
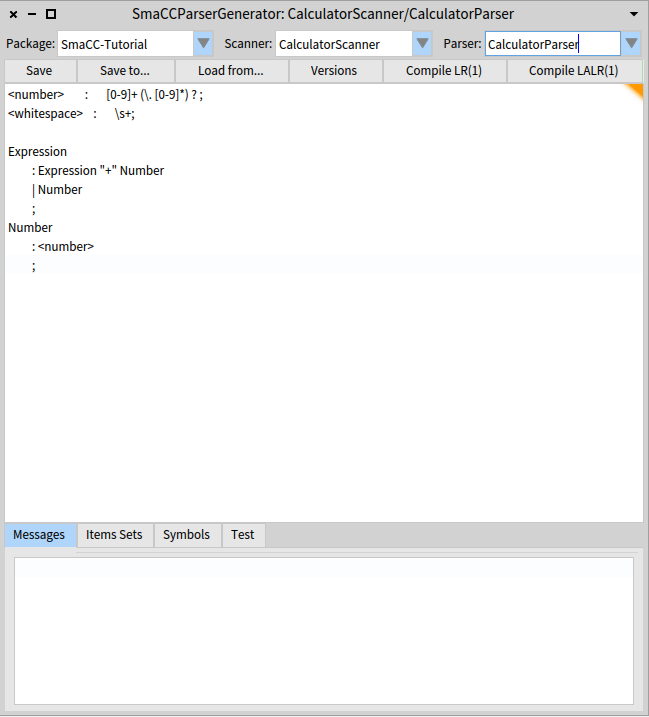
Speaking of the grammar, let's go ahead and define it. Enter the following specification below your two previous rules in the editor pane, as shown in Figure .
Expression
: Expression "+" Number
| Number
;
Number
: <number>
;This basically says that an expression is either a number, or an expression added to a number. You should now have something that looks like Figure .
Compile the Scanner and the Parser
We are almost ready to compile a parser now, but first we need to specify the names of the scanner and parser classes that SmaCC will create. These names are entered using the ... buttons for scanner class and parser class. Enter CalculatorScanner and CalculatorParser respectively. Once the class names are entered, press Compile LR(1) or Compile LALR(1). This will create new Pharo classes for the CalculatorScanner and CalculatorParser, and compile several methods in those classes. All the methods that SmaCC compiles will go into a "generated" method protocol. You should not change those methods or add new methods to the "generated" method protocols, because these methods are replaced or deleted each time you compile.
Whenever SmaCC creates new classes, they are placed in the package (or package tag) named in the Package entry box. You may wish to select a different package by selecting it in the drop down menu or writing its name.
Testing our Parser
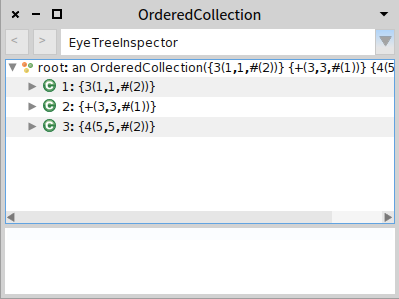
Now we are ready to test our parser. Go to the "test" pane, enter 3 + 4, and press "Parse"; you will see that the parser correctly parses it. If you press "Parse and inspect" you will see an inspector on an OrderedCollection that contains the parsed tokens, as shown in Figure . This is because we haven't specified what the parser is supposed to do when it parses.
You can also enter incorrect items as test input. For example, try to parse 3 + + 4 or 3 + a. An error message should appear in the text.
If you are interested in the generated parser, you may wish to look at the output from compiling the parser in the Symbols or Item Sets tab.
- The Symbols tab lists all of the terminal and non-terminal symbols that were used in the parser. The number besides each is the internal id used by the parser.
- The Item Sets tab lists the LR item sets that were used in the parser. These are printed in a format that is similar to the format used by many text books.
- The Messages tab is used to display any warnings generated while the parser was compiled. The most common warning is for ambiguous actions.
Defining Actions
Now we need to define the actions that need to happen when we parse our expressions. Currently, our parser is just validating that the expression is a bunch of numbers added together. Generally, you want to create some structure that represents what you've parsed (e.g., a parse tree). However, in this case, we are not concerned about the structure, but we are concerned about the result: the value of the expression. For our example, we can calculate the value by modifying the grammar to be:
Expression
: Expression "+" Number {'1' + '3'}
| Number {'1'}
;
Number
: <number> {'1' value asNumber}
;
The text between the braces is Pharo code that is evaluated when the grammar rule is applied. Strings that contain a number are replaced with the corresponding expression in the production. For example, in the first rule for Expression, the '1' will be replaced by the object that matches Expression, and the '3' will be replaced by the object that matches Number.
The second item in the rule is the "+" token. Since we already know what it is, there is no need to refer to it by number.
Compile the new parser. Now, when you do a 'Parse and inspect' from the test pane containing 3 + 4, you should see the result: 7.
Named Expressions
One problem with the quoted numbers in the previous example is that if you change a rule, you may also need to change the code for that rule. For example, if you inserted a new token at the beginning of the rule for Expression, then you would also need to increment all of the numeric references in the Pharo code.
We can avoid this problem by using named expressions. After each part of a rule, we can specify its name. Names are enclosed in single quotes, and must be legal Pharo variable names. Doing this for our grammar we get:
Expression
: Expression 'expression' "+" Number 'number' {expression + number}
| Number 'number' {number}
;
Number
: <number> 'numberToken' {numberToken value asNumber}
;This will result in the same language being parsed as in the previous example, with the same actions. Using named expressions makes it much easier to maintain your parsers.
Extending the Language
Let's extend our language to add subtraction. Here is the new grammar:
Expression
: Expression 'expression' "+" Number 'number' {expression + number}
| Expression 'expression' "-" Number 'number' {expression - number}
| Number 'number' {number}
;
Number
: <number> 'numberToken' {numberToken value asNumber}
;
After you've compiled this, '3 + 4 - 2' should return '5'. Next, let's add multiplication and division:
Expression
: Expression 'expression' "+" Number 'number' {expression + number}
| Expression 'expression' "-" Number 'number' {expression - number}
| Expression 'expression' "*" Number 'number' {expression * number}
| Expression 'expression' "/" Number 'number' {expression / number}
| Number 'number' {number}
;
Number
: <number> 'numberToken' {numberToken value asNumber}
;Handling Priority
Here we run into a problem.
If you evaluate '2 + 3 * 4' you end up with 20.
The problem is that in standard arithmetic, multiplication has a higher precedence than addition.
Our grammar evaluates strictly left-to-right.
The standard solution for this problem is to define additional non-terminals to force the sequence of evaluation.
Using that solution, our grammar would look like this.
Expression
: Term 'term' {term}
| Expression 'expression' "+" Term 'term' {expression + term}
| Expression 'expression' "-" Term 'term' {expression - term}
;
Term
: Number 'number' {number}
| Term 'term' "*" Number 'number' {term * number}
| Term 'term' "/" Number 'number' {term / number}
;
Number
: <number> 'numberToken' {numberToken value asNumber}
;
If you compile this grammar, you will see that '2 + 3 * 4' evaluates to '14', as you would expect.
Handling Priority with Directives
As you can imagine, defining additional non-terminals gets pretty complicated as the number of levels of precedence increases. We can use ambiguous grammars and precedence rules to simplify this situation. Here is the same grammar using precedence to enforce our desired evaluation order:
%left "+" "-";
%left "*" "/";
Expression
: Expression 'exp1' "+" Expression 'exp2' {exp1 + exp2}
| Expression 'exp1' "-" Expression 'exp2' {exp1 - exp2}
| Expression 'exp1' "*" Expression 'exp2' {exp1 * exp2}
| Expression 'exp1' "/" Expression 'exp2' {exp1 / exp2}
| Number 'number' {number}
;
Number
: <number> 'numberToken' {numberToken value asNumber}
;
Notice that we changed the grammar so that there are Expressions on both sides of the operator.
This makes the grammar ambiguous: an expression like '2 + 3 * 4' can be parsed in two ways.
This ambiguity is resolved using SmaCC's precedence rules.
The two lines that we added to the top of the grammar mean that + and - are evaluated left-to-right and have the same precedence.
Likewise, the second line means that * and / are evaluated left-to-right and have equal precedence.
Because the rule for + and - comes first, + and - have lower precedence than * and /.
Grammars using precedence rules are usually much more intuitive, especially in cases with many precedence levels.
Just as an example, let's add exponentiation and parentheses.
Here is our final grammar:
<number> : [0-9]+ (\. [0-9]*) ? ;
<whitespace> : \s+;
%left "+" "-";
%left "*" "/";
%right "^";
Expression
: Expression 'exp1' "+" Expression 'exp2' {exp1 + exp2}
| Expression 'exp1' "-" Expression 'exp2' {exp1 - exp2}
| Expression 'exp1' "*" Expression 'exp2' {exp1 * exp2}
| Expression 'exp1' "/" Expression 'exp2' {exp1 / exp2}
| Expression 'exp1' "^" Expression 'exp2' {exp1 raisedTo: exp2}
| "(" Expression 'expression' ")" {expression}
| Number 'number' {number}
;
Number
: <number> 'numberToken' {numberToken value asNumber}
;
Once you have compiled the grammar, you will be able to evaluate 3 + 4 * 5 ^ 2 ^ 2 to get 2503.
Since the exponent operator ^ is defined to be right associative, this expression is evaluated as 3 + (4 * (5 ^ (2 ^ 2))).
We can also evaluate expressions with parentheses.
For example, evaluating (3 + 4) * (5 - 2) ^ 3 results in 189.
The sections that follow provide more information on SmaCC's scanner and parser, and on the directives that control SmaCC.
Subsequent sections explain how SmaCC can automatically produce an AST for you and how to use the Rewrite Engine.